Label Join#
What does label join job do#
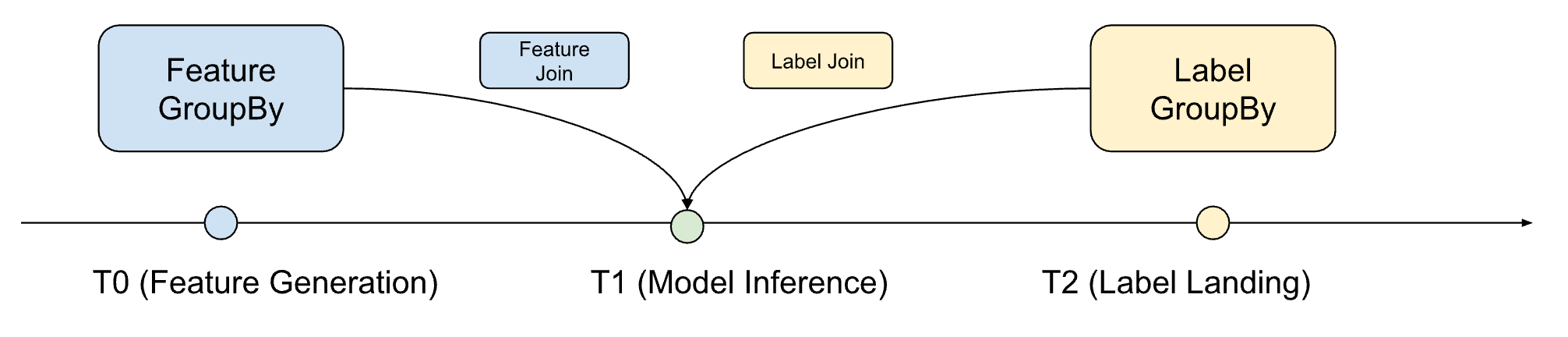
Beside feature generation, another common step in dataset preparation for ML is the generation of labels and joining of labels and features, where in general, we have: feature generation timestamp < inference timestamp <= label landing timestamp
The label join allows generation of offline labeled datasets with associated features. Once regular join backfilling processes are complete, you can initiate a Label Join job to incorporate available labels into the feature set, resulting in a comprehensive training dataset. This enables access to all labeled features, including a ‘Labeled Latest’ table that conveniently provides the most recent available label version for analysis purposes.
We provide support for both non-aggregated labels and labels that require aggregation. Label aggregations function similarly to regular feature group-by aggregations, and existing operations can also be applied to labels.
How does label join work?#
Including a label_part to your join creates a new set of workflows to create label tables and a labeled training set view for the join.
LabelJoin reuses GroupBy, a key compute primitive in Chronon that is also used to generate and serve features. The same set of aggregations are reused to created aggregated label values.
v2 = Join(
left=...,
right_parts=[...],
label_part=LabelPart(
labels=[
JoinPart(group_by=label_part_group_by)
],
left_start_offset=30,
left_end_offset=10,
label_offline_schedule="@weekly"
)
)
Label GroupBy builds label values by key as of label landing time
left_start_offset/left_end_offset specifies time offsets between Model Inference time and Label Landing time. See below for more examples
Internally, Chronon
(1) joins the label source table with the left table to create a materialized label table, and
(2) maintains a Hive view that joins the materialized label table (which doesn’t have feature data) with the join table.
The (2) result is not materialized for cost efficiency consideration.
Label Join without Aggregations#
Label Join’s GroupBy can take in a pre-aggregated label source.
Breakdown of the parameters
label_part_group_byleverages a pre-aggregated label source, keyed on group_by_subjectleft_start_offsetis 30 andleft_end_offsetis 10 respectively. This means that for each label value on date_x, it will be joined back to left rows with ds in [date_x - 30, date_x - 10].
Essentially, this achieves a “30 to 10 day” maturity scheme, where for each inference event, labels landed in the next between 30 and 10 days are being aggregated and attributed back to the inference event.
```python
label_part_group_by = GroupBy(
name="sample_label_group_by",
sources=test_sources.batch_entity_source,
keys=["group_by_subject"],
aggregations=None,
online=False,
)
v2 = Join(
left=test_sources.event_source,
output_namespace="sample_namespace",
right_parts=[
JoinPart(
group_by=event_sample_group_by.v1,
key_mapping={'subject': 'group_by_subject'},
),
JoinPart(
group_by=group_by_with_kwargs.v1,
key_mapping={'subject': 'group_by_subject'},
),
],
label_part=LabelPart([
JoinPart(
group_by=label_part_group_by
),
],
left_start_offset=30,
left_end_offset=10,
label_offline_schedule="@weekly"
)
)
Label Join with Aggregations#
Label GroupBy with aggregation is similar to without-aggregation case, except that an additional GroupBy aggregation is applied first to the raw sources, before joining to the (feature) rows. The aggregation semantics fully reuse what GroupBy supports for feature aggregation.
Breakdown of the parameters
label_part_group_bydefines a label aggregation that is a 7-window SUM over the source tableleft_start_offsetandleft_end_offsetis both set to 7. This means that for each label value on ds_label, it will be joined back to left rows on ds_label - 7.
Essentially, this achieves a “7-day” label landing scheme, where for each inference event, labels landed in the next 7 day are being aggregated and attributed back to the inference event.
label_part_group_by = GroupBy(
name="sample_label_group_by",
sources=test_sources.entity_source,
keys=["group_by_key"],
aggregations=[
Aggregation(input_column="group_by_key", operation=Operation.SUM, windows=[Window(7, TimeUnit.DAYS)]),
],
online=False,
)
v2 = Join(
left=test_sources.event_source,
output_namespace="sample_namespace",
right_parts=[
JoinPart(
group_by=event_sample_group_by.v1,
key_mapping={'subject': 'group_by_key'},
),
JoinPart(
group_by=group_by_with_kwargs.v1,
key_mapping={'subject': 'group_by_key'},
),
],
label_part=LabelPart([
JoinPart(
group_by=label_part_group_by
),
],
left_start_offset=7,
left_end_offset=7,
label_offline_schedule="@weekly"
),
)
What do output tables look like?#
Output tables
Regular join feature backfill table
Joined view with features and labels. On the fly and not materialized
Joined view with feature and latest labels available. On the fly and not materialized
Examples:
my_team_my_join_v1
my_team_my_join_v1_labeled
my_team_my_join_v1_labeled_latest
Sample Schema of my_team_my_join_v1_labeled
Column | Type | Extra | Comment
-------------------------------------------+---------+-------+---------
reservation | bigint | |key
ds | varchar | |ds
guest | bigint | |key
listing | bigint | |key
feature_col_1 | varchar | |feature
feature_col_2 | varchar | |feature
feature_col_3 | varchar | |feature
label_col_1 | integer | |label
label_col_2 | integer | |label
label_col_3 | integer | |label
label_ds | varchar | |label version
Sample Schema of my_team_my_join_v1_labeled_latest
Schema is same as my_team_my_join_v1_labeled but with a different set of data:
If a particular date has multiple label versions like 2023-01-24, 2023-02-01, 2023-02-08:
Only the latest label from 2023-02-08 would show up in
my_team_my_join_v1_labeled_latestInstead, all three label would show up in
my_team_my_join_v1_labeledtable
Column | Type | Extra | Comment
-------------------------------------------+---------+-------+---------
reservation | bigint | |key
ds | varchar | |ds
guest | bigint | |key
listing | bigint | |key
feature_col_1 | varchar | |feature
feature_col_2 | varchar | |feature
feature_col_3 | varchar | |feature
label_col_1 | integer | |label
label_col_2 | integer | |label
label_col_3 | integer | |label
label_ds | varchar | |label version