Aggregations#
Supported aggregations#
All supported aggregations are defined here. Chronon supports powerful aggregation patterns and the section below goes into detail of the properties and behaviors of aggregations.
Simple Aggregations#
count, average, variance, min, max, top_k, bottom_k are some self-describing and simple aggreagations.
Time based Aggregations#
last, first, last_k, first_k aggregations are timed aggregations and require users to define a
GroupBy.sources[i].query.time_column with a valid expression that produces a millisecond-granular timestamp as a Long.
All windowed aggregations require the user to define the time_column as well.
To accommodate common conventions, when time_column is not specified, but required,
Chronon will look for a ts column from the input source.
Sketching Aggregations#
Sketching algorithms are used to approximate the values of an exact aggregation when the aggregation itself is not
scalable. unique_count and percentile aggregations are examples where getting exact value requires storing all raw
values, and hence not-scalable. approx_unique_count and approx_percentile aggregations utilize a bounded amount of
memory to estimate the value of the exact aggregation. We allow users to tune this trade-off between memory and accuracy
as a parameter to the Aggregation. Chronon as a policy doesn’t encourage use of un-scalable aggregations.
unique_count and histogram are supported but discouraged due to lack of scalability.
Internally we leverage Apache DataSketches library as a source of SOTA algorithms
that implement approximate aggregations with the most efficient performance.
Reversible Aggregations#
Chronon can consume a stream of db mutations to produce read-optimized aggregate views. For example - computing max
purchase_price for a user from a user_purchases source. For user alice, if the max that is being maintained so
far, gets update-ed and lowered in the db table, it would be impossible to know what the new max should be
without maintaining a complete list of all purchase prices. However this is not the case with average of
purchase_price. It is possible to store sum and count separately and adjust the sum and count when a row with
purchase_price gets update-ed, delete-ed or insert-ed.
However during online serving we asynchronously (in the background) batch-correct the aggregates by going over full data. So even non-reversible aggregations reflect the right aggregate value eventually without sacrificing scalability.
Windowing#
We support arbitrarily large windows with HOURS-ly or DAYS-ly granularity. Chronon supports what is called a
sawtooth window. To understand sawtooth windows we need to understand sliding windows and hopping windows.
Un-windowed aggregation or life-time aggregation is performed when windows argument is not specified to the
Aggregation.
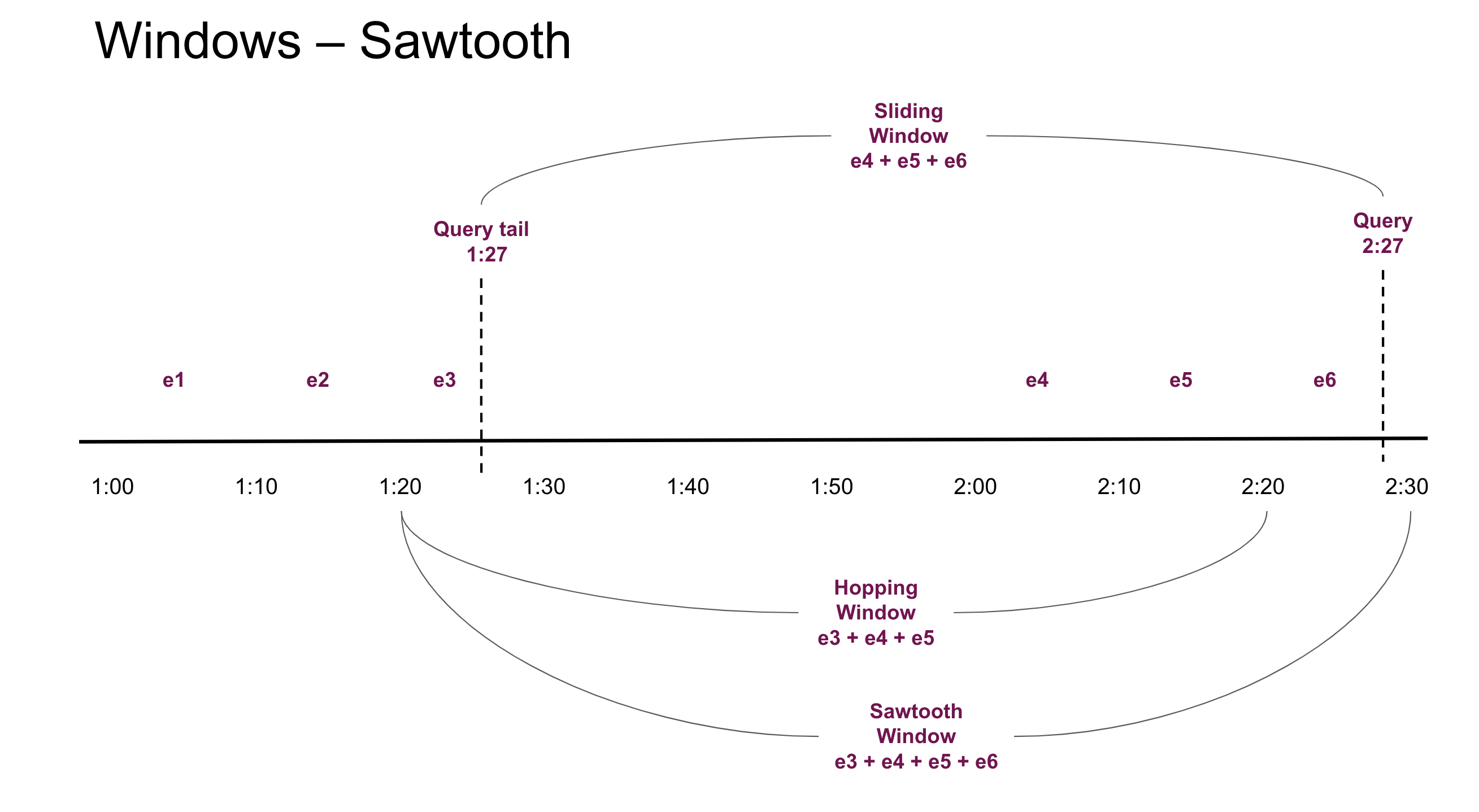
Sliding Windows - a query at 2:27pm for an aggregation defined to be 1 hour long would span from 1:27pm to
2:27pm. This type of aggregation requires us to store all raw events which is a scaling bottleneck.
Hopping Windows - hopping windows remedy the requirement to store all the individual events by aggregating the
events into a hop, a fixed time-interval. So a 1hr window with a 10 minute hops will divide the window into 6 hops
that are fixed. At 2:27pm the hops go from 1:20 . 1:30 . 1:40 . 1:50 . 2:00 . 2:10 . 2:20. Effectively the
aggregation range is 1:20 - 2:20. Which is a 1 hour window but misses all the events between 2:20 and 2:27 and is
hence stale - missing most recent events. This is not accepable for machine learning use-cases.
Sawtooth Windows - union of sliding and hopping windows. So we get the benefit of constant (low) memory usage of
hopping windows without the loss of most recent events. Sawtooth windows will have variable window interval size - and
in this particular example we will aggregate events between 1:20 - 2:27.
TODO: Windowing Code Example
Bucketing#
Expanding on the previous example - if we wanted to compute average purchase_price of a user_purchase source, but
bucketed by credit_card. So instead of producing a single double value, bucketing produces a map of credit_card to
average_purchase_price.
Chronon can accept multiple bucket columns at once and Bucketing is specified as GroupBy.aggregations[i].buckets.
Bucketing always produces a map, and for online use-cases we require the bucket column to be a string. This requirement
comes from Chronon’s usage of avro in the serving environment. We plan to mitigate requirement at a later time.
TODO: Bucketing Code Example
Flattening#
Chronon can extract values nested in containers and perform aggregations - over lists and maps. See details below for semantics.
Lists as inputs#
Aggregations can also accept list columns as input. For example if we want average item_price from a user_purchase
source, which contains item_prices as a list of values in each row - represented by a single credit card transaction.
Simply put, GroupBy.aggregations[i].input_column can refer to a columnname which contains lists as values. In
traditional SQL this would require an expensive explode command and is supported natively in Chronon.
Maps as inputs#
Aggregations over columns of type ‘Map<String, Value>’. For example - if you have two histograms this will allow for merging those histograms using - min, max, avg, sum etc. You can merge maps of any scalar values types using aggregations that operate on scalar values. The output of aggregations with scala values on map types is another map with aggregates as values.
Limitations:
Map key needs to be string - because avro doesn’t like it any other way
Map aggregations cannot be coupled with bucketing for now. We will add support later.
Aggregations need to be time independent for now - will add support for timed version later.
NOTE: Windowing, Bucketing and Flattening can be flexibly mixed and matched.#
Table of properties for aggregations#
aggregation |
input type |
nesting allowed? |
output type |
reversible |
parameters |
bounded memory |
|---|---|---|---|---|---|---|
count |
all types |
list, map |
long |
yes |
yes |
|
min, max |
primitive types |
list, map |
input |
no |
yes |
|
top_k, bottom_k |
primitive types |
list, map |
list<input,> |
no |
k |
yes |
first, last |
all types |
NO |
input |
no |
yes |
|
first_k, last_k |
all types |
NO |
list<input,> |
no |
k |
yes |
average, variance |
numeric types |
list, map |
double |
yes |
yes |
|
histogram |
string |
list, map |
map<string, long> |
yes |
k=inf |
no |
approx_unique_count |
primitive types |
list, map |
long |
no |
k=8 |
yes |
approx_percentile |
primitive types |
list, map |
list<input,> |
no |
k=128, percentiles |
yes |
unique_count |
primitive types |
list, map |
long |
no |
no |
Tuning#
If you look at the parameters column in the above table - you will see k.
k for top_k, bottom_k, first_k, last_k tells Chronon to collect k elements.
For approx_unique_count and approx_percentile - k stands for the size of the sketch - the larger this is, the more
accurate and expensive to compute the results will be. Mapping between k and size for approx_unique_count is
here
for approx_percentile is the first table in here.
percentiles for approx_percentile is an array of doubles between 0 and 1, where you want percentiles at. (Ex: “[0.25, 0.5, 0.75]”)
For histogram - k keeps the elements with top-k counts. By default we keep everything.